Machine Learning.
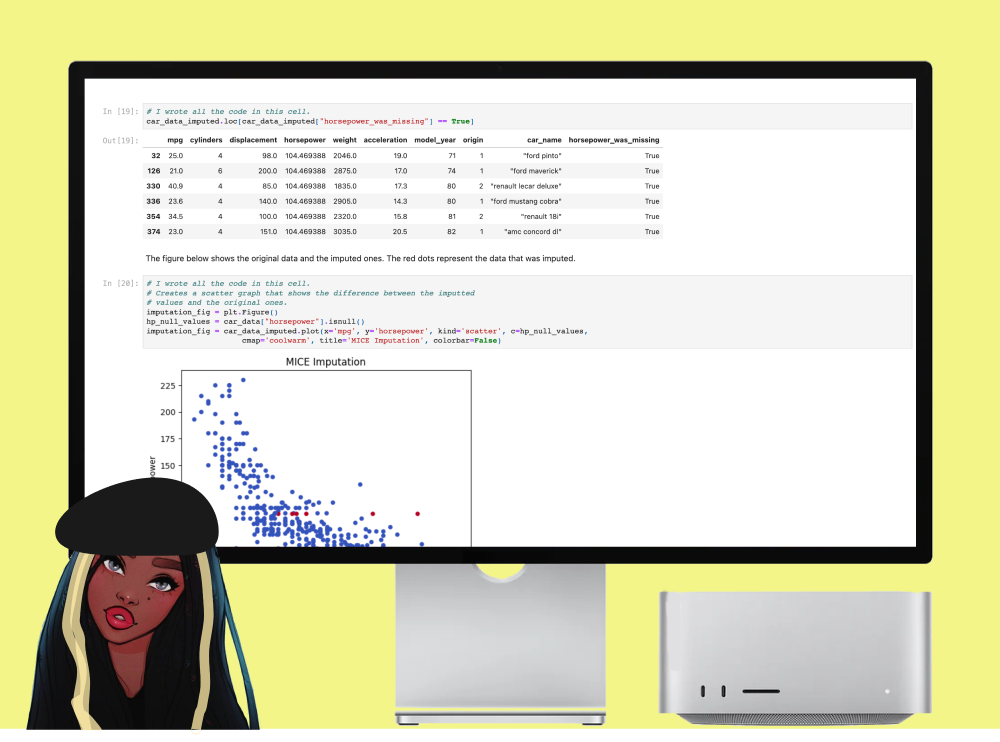
Is your car draining your wallet?
In this project, I conducted a comprehensive analysis of factors affecting a car's miles per gallon (MPG) and built a predictive model to estimate MPG based on key features. Through data analysis and visualisation, I explored correlations between displacement, horsepower, weight, and continent of origin with MPG, identifying negative correlations and outliers. Utilising machine learning techniques, I developed a linear regression model using features like displacement, horsepower, and weight, and evaluated its performance using metrics like R2 score, mean squared error (MSE), and mean absolute error (MAE). Subsequent validation using cross-validation revealed initial overfitting, prompting the implementation of feature engineering techniques such as log and exponential transforms to improve model performance. Re-evaluation of the model post-feature engineering showed slight improvements in performance metrics. While acknowledging the study's limitations, such as dataset size and other unaccounted factors, the project underscores the iterative nature of model development and the importance of feature engineering in enhancing predictive accuracy.
I accomplished the following:
- Conducted comprehensive analysis of factors influencing car MPG and built predictive model for estimating MPG.
- Explored correlations between displacement, horsepower, weight, and continent of origin with MPG through data analysis and visualisation.
- Developed linear regression model utilising features like displacement, horsepower, and weight.
- Evaluated model performance using metrics like R2 score, mean squared error (MSE), and mean absolute error (MAE).
- Detected initial overfitting in model and addressed it through implementation of feature engineering techniques.
- Implemented log and exponential transforms to address skewness and capture potential non-linear relationships in features.
- Re-evaluated model post-feature engineering, observing slight improvements in performance metrics.
- Acknowledged study limitations including dataset size and unaccounted factors.
- Demonstrated iterative nature of model development and emphasized importance of feature engineering in improving predictive accuracy.
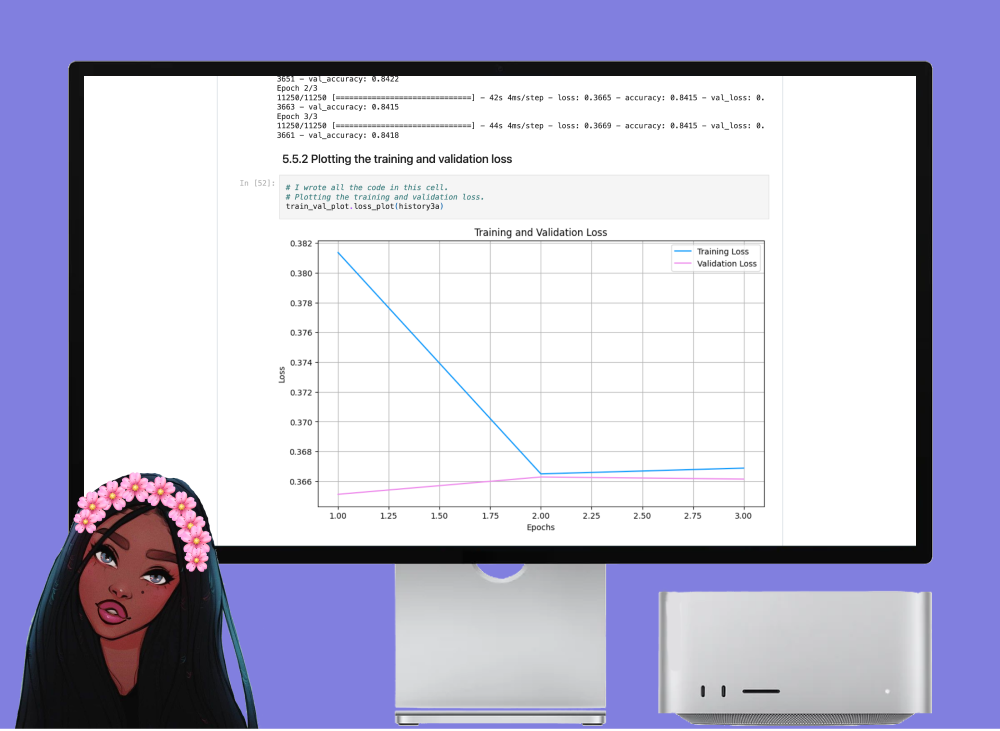
Can machines understand how you feel?
In this project, I undertook the task of building and evaluating a sentiment analysis model for Amazon reviews. Beginning with data preprocessing, I cleaned and prepared the dataset for analysis. Next, I implemented various deep learning architectures using TensorFlow and Keras, experimenting with different model configurations, activation functions, learning rates, and dropout layers. Through systematic experimentation and evaluation, I identified the most effective model architecture for predicting sentiment in Amazon reviews. Notably, I achieved a balance between model performance and generalization to unseen data, with both training and testing accuracies exceeding 86%. Moreover, I thoroughly documented each step of the process, providing detailed analysis and insights into the model's performance. Overall, this project showcases my proficiency in natural language processing, deep learning, and experimental design, highlighting my ability to tackle complex tasks in machine learning and produce actionable insights.
I accomplished the following:
- Developed a sentiment analysis model for Amazon reviews using deep learning techniques.
- Conducted comprehensive data preprocessing to clean and prepare the dataset for analysis.
- Implemented various deep learning architectures using TensorFlow and Keras.
- Experimented with different model configurations, including layers, units, activation functions, and learning rates.
- Explored the impact of dropout layers on model performance to prevent overfitting.
- Systematically evaluated model performance through training and testing accuracy metrics.
- Achieved a balance between model performance and generalisation to unseen data, with accuracies exceeding 86%.
- Provided detailed documentation and analysis of each experimentation step, demonstrating proficiency in experimental design.
- Demonstrated skills in natural language processing, deep learning, and machine learning experimentation.
- Produced actionable insights into sentiment analysis for Amazon reviews, highlighting potential applications in business intelligence and customer feedback analysis.
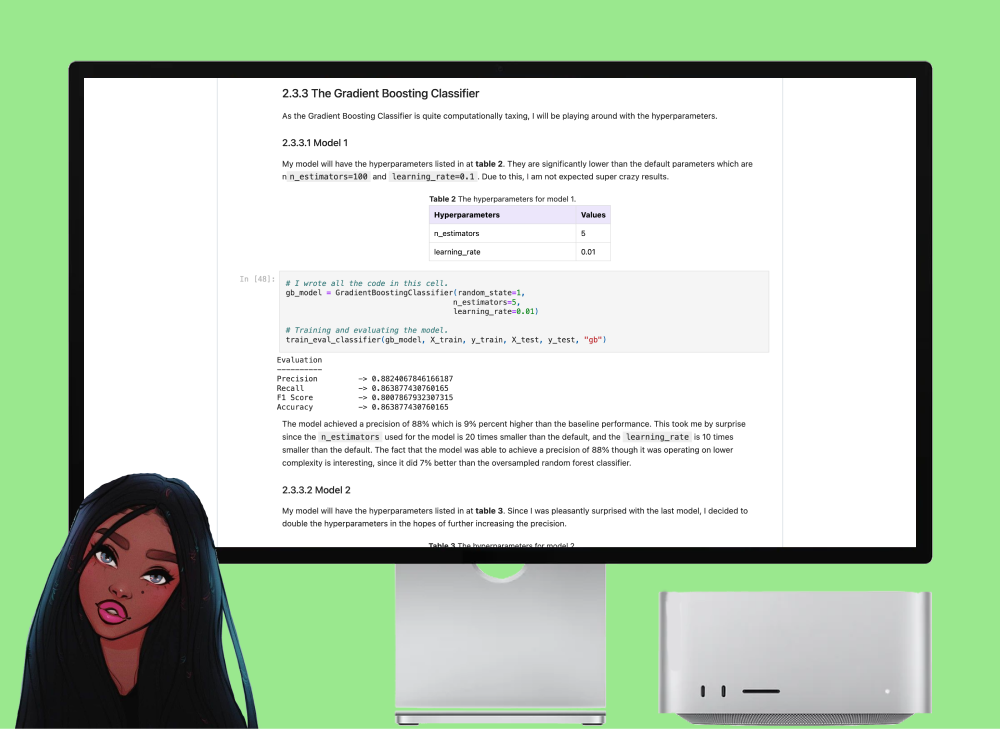
Machine Vs Humans
In this project, I conducted a comprehensive exploration of various machine learning models for hate speech detection, focusing on precision as the primary evaluation metric. Beginning with random forest classifiers, I experimented with oversampling techniques to mitigate class imbalance but observed only modest improvements over the baseline performance. Transitioning to gradient boosting classifiers, I meticulously tuned hyperparameters to optimize model precision. Surprisingly, even with lower model complexity, gradient boosting models consistently outperformed random forest models, showcasing the importance of algorithm selection and parameter tuning. Despite encountering practical constraints such as limited computational resources and dataset size, I successfully built models that surpassed the baseline precision, ultimately achieving a maximum precision of 88%. This project not only fulfilled its objectives of exploring natural language models and improving hate speech classification but also provided valuable insights into the complexities and challenges of text classification tasks.
I accomplished the following:
- Conducted comprehensive exploration of machine learning models for hate speech detection.
- Focused on optimising precision as the primary evaluation metric.
- Experimented with random forest classifiers and oversampling techniques to mitigate class imbalance.
- Transitioned to gradient boosting classifiers and meticulously tuned hyperparameters for optimal performance.
- Surpassed baseline precision by achieving a maximum precision of 88%.
- Acknowledged practical constraints such as limited computational resources and dataset size.
- Successfully met project objectives of exploring natural language models and improving hate speech classification.
- Gained valuable insights into the complexities and challenges of text classification tasks.